How Weco's Autoresearch Improved a Production Fraud Detection Pipeline

"Weco has helped us automate months of engineering work and close multiple customer contracts."
Most machine learning models learn from historical data and apply those lessons to future predictions.
Adversarial ML is different. In domains like fraud, risk, and trust & safety, bad actors are constantly changing their behavior to avoid detection. New attack patterns emerge, and models trained on last quarter's data miss this quarter's attacks. Every point of model performance matters: missed fraud turns into direct losses, and false positives turn away paying customers.
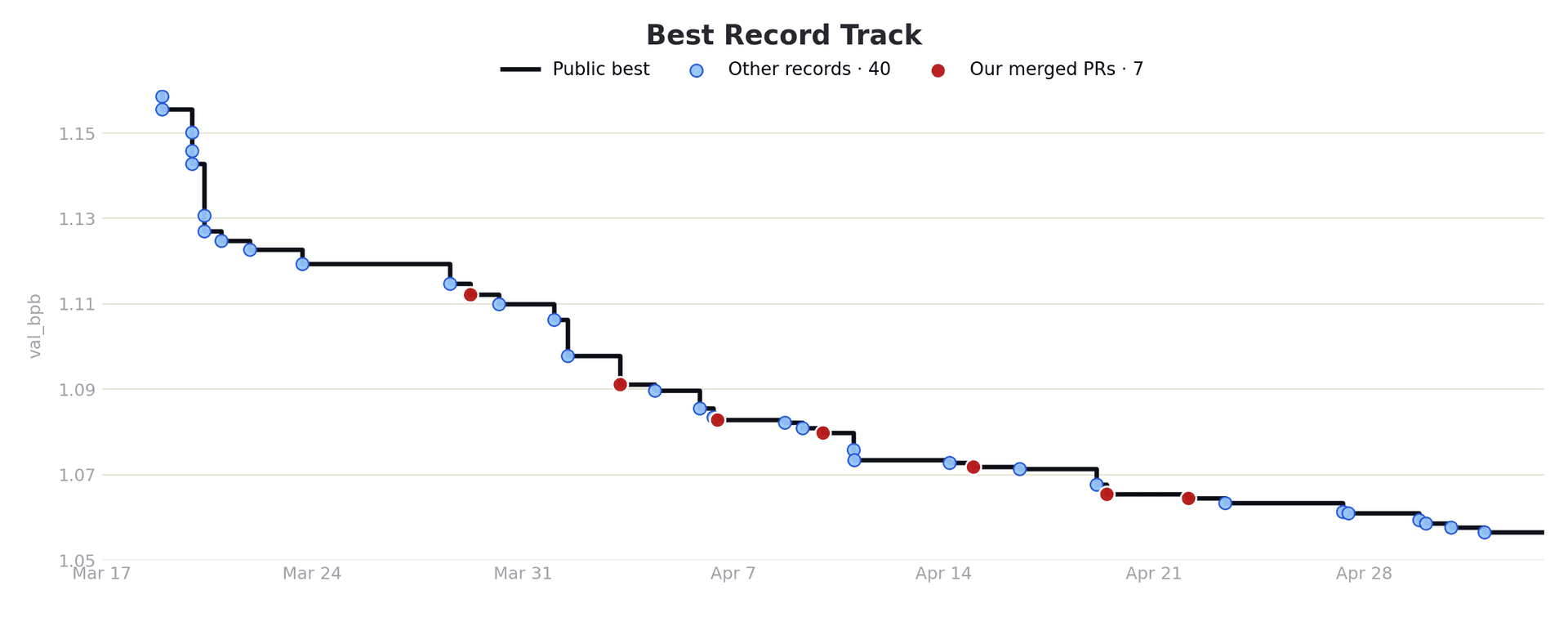
Vardera, an AI-driven authentication platform, hit a ceiling on their fraud classifiers earlier this year. Then they pointed Weco's autoresearch agent at their codebase. Within a single Weco optimization run, F1 climbed 17.7%, and precision climbed another 18.9% across follow-on runs. They've since run 200+ Weco optimizations across the rest of their pipeline, lifting their key fraud detection metrics by over 50%.
|
+17.7%
F1 on the first Weco run against their PMI classifier
|
+18.9%
precision at recall ≥ 0.40 across CatBoost runs
|
200+
Weco runs across Vardera's pipeline since
|
Background
Vardera uses AI to discern real high-value items from fakes. Resellers, auction houses, and collectors rely on Vardera to authenticate everything from coins to luxury goods before a deal closes. Their ML pipeline scores each listing for authenticity using image, text, and metadata signals, with a decision layer combining them.
Like every team running adversarial ML, Vardera hit a structural wall. Hyperparameter tuning, ensembling, and adding more data all showed diminishing returns past a competent baseline. The remaining headroom lives in the code itself ( features, model architecture, decision logic) which is the slowest and most expensive layer to iterate on. And hiring another ML engineer costs $200K+ a year plus months of onboarding without changing iteration speed.
Beneath all of this sat a single constraint: a classification model improves only as fast as an engineer can propose, build, and test new features and architectures, one experiment at a time.
What Weco actually did
Weco operates as an automated ML engineer. You point it at your training pipeline, set the metric you want moved, and walk away. An LLM proposes code changes, an evaluator built from your metric and data scores each one, and a tree search keeps context across attempts so good branches get extended and dead ends get pruned. Every change Weco proposes ships as auditable code — reviewable as a normal PR, with no black-box embeddings.
For Vardera, the first Weco run targeted F1 on the PMI-based scoring approach. F1 moved from 0.583 to 0.686 (+17.7%) and along the way, Weco wrote features the team hadn't written.
Subsequent runs came after the team tightened their operating metric to precision at recall ≥ 0.40 and switched the underlying model to CatBoost. Across those runs, precision climbed from 0.789 to 0.938 (+18.9%) and 100+ iterations later, Jun summarized the cumulative result as a ~50% improvement on their metrics.
| Metric | Before | After | Change |
|---|---|---|---|
| F1 (PMI scoring) | 0.583 | 0.686 | +17.7% |
| Precision at recall ≥ 0.40 (CatBoost) | 0.789 | 0.938 | +18.9% |
The features it wrote
The interesting part isn't the score, but what Weco actually wrote. A few patterns recurred across runs, and they generalize past any single classification problem:
- Cross-field contradictions. When one field disagrees with another it claims to describe. For Vardera, that surfaced as year-of-issue declared in a title vs. tagged in metadata. The same shape generalizes to declared vs. observed device type, stated vs. measured geography, claimed credential vs. inferred capability.
- Joint encodings of individually-neutral features. A high-risk region paired with a high-value item class, scored as a single interaction rather than two additive signals.
- Granular decomposition of aggregate scores. Splitting a single risk score into its component counts — risky / safe / total — and using each as an independent input.
- Stylometric signals in free text. Capitalization ratio, repetition density in one field but not another, disclaimer text appearing in a description but absent from the title.
- Missing data as information. Treating an absent certification tag as suspicious rather than neutral when the rest of the listing makes a strong claim.
These aren't features AutoML proposes, because AutoML doesn't touch feature code. They aren't what a general-purpose LLM coding loop converges on inside a sane budget either. They surface when a code-level search has enough context to explore a domain and enough selection pressure to keep what works.
Vardera has since run 200+ Weco optimizations across the rest of their pipeline. The team also began using Weco as a second phase of training — running it on model outputs against ground truth to push final classifier accuracy higher.
"Using Weco has improved our ability to go from 90% to 99%. After training models, we let Weco hill climb with our model outputs against ground truth as a second phase of training."
— Jun Cho, ML Engineer at Vardera
What changed
The bigger shift isn't the lift on any single metric. It's that the iteration cadence stopped being bound by how fast an engineer could propose new features.
Every ML team's improvement loop is rate-limited by code throughput — one experiment at a time, one engineer's working memory. Weco runs that loop in the background, in parallel, until the metric stops moving. Continuous re-optimization against drift becomes tractable rather than a budget decision; re-running on new data doesn't register against any serious loss rate.
Every change Weco proposes is ordinary code. Vardera reads it, reviews it, and version-controls it like any other PR. There's no black-box embedding, no model-as-a-service handoff. For teams shipping into regulated environments — financial services, identity verification, authentication — model-risk documentation, fairness checks, and reason codes keep working, because the model stays the team's model.
Vardera didn't replace their ML engineer. They gave the one they already had a second one that ran overnight.
Try it on your own pipeline
The fastest way to find out whether Weco moves your metric is to point it at the pipeline you already have. Install the CLI, then give it the file you want optimized and the command that evaluates it:
pip install weco
weco run --source train.py \
--eval-command "python evaluate.py" \
--metric recall_at_fpr \
--goal maximize \
--steps 50
--source is the file Weco rewrites. --eval-command is whatever you
already run to score a model. If you'd rather see it run on your own stack first,
book a 20-minute call.