Weco Is Now in Public Beta
Much of machine learning is a persistent grind of trial and error.
As ML practitioners, we spend a huge portion of our time testing ideas. We try a new data augmentation, a different learning rate, a modified architecture, or a re-written prompt. We wait for the job to run, analyze the results, and start the loop all over again.
But you only have a finite number of attempts. This leads to the ever lasting dilemma:
- Did the current approach fail because I didn't pull the lever hard enough?
- Or have I been too attached to the idea, and it's time to go back to exploration mode?
Staying late or being more experienced helps, but what if being able to automatically test 10x more ideas?
Key Takeaways
- Weco automates the ML trial-and-error loop, testing hundreds of ideas against your evaluation metric overnight.
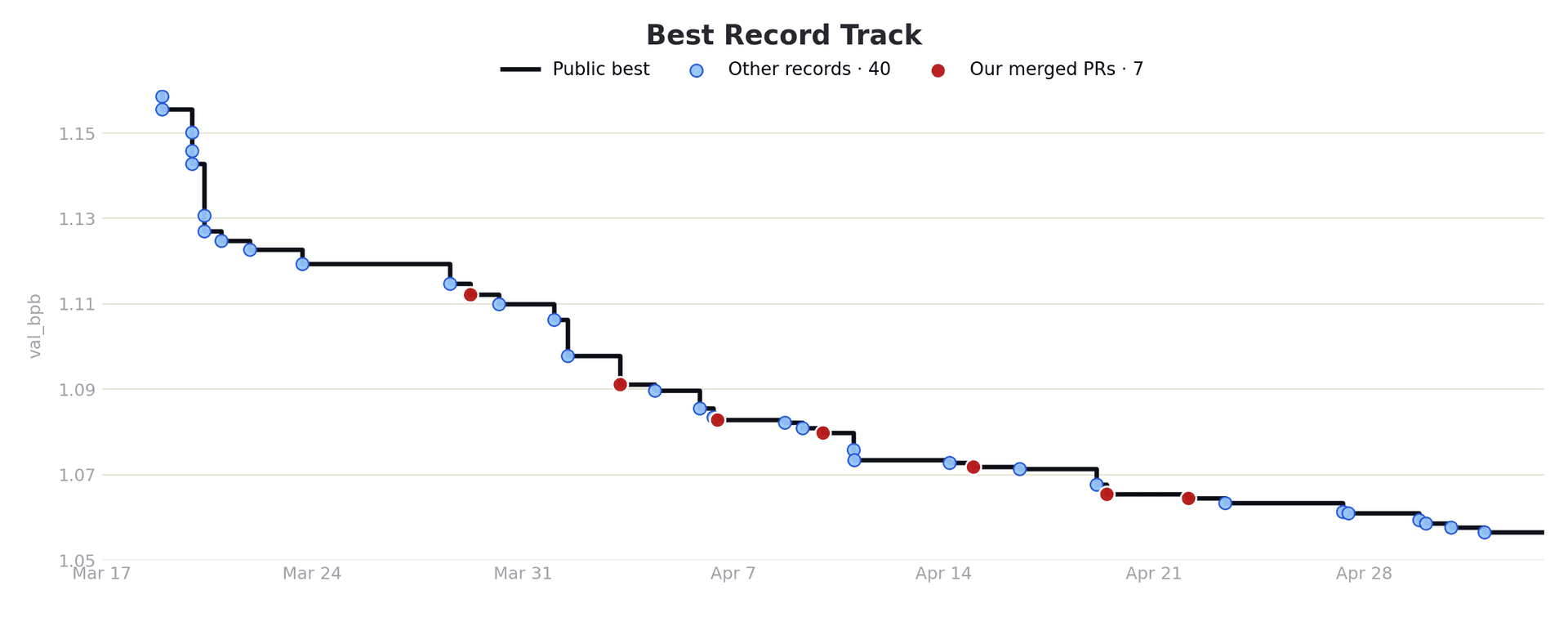
- In a live CrunchDAO competition, Weco placed in the top 10% (34th of 490 teams) for just $20 over 17 days.
- Users are applying Weco to prompt engineering, kernel optimization, network architecture tuning, and more.
- Weco is the evolution of AIDE, the top-performing system on OpenAI's MLE-Bench for ML engineering tasks.
How Does Weco's Automated Exploration Loop Work?
Weco drives an automated loop for empirical exploration. The methodology is straightforward:
- Define the Eval: You, or you plus your coding agent, write an evaluation script that measures the performance of any given solution. Could be speed, accuracy, cost, or simply any metric.
- Weco Explores: The system takes over, running a continuous loop to propose new ideas, implement them against your codebase, and test them empirically using the exact evaluation script you provided.
Instead of you manually trying 20 ideas over a week, the system can test hundreds overnight.
Goodhart-Proof Benchmark
The predecessor of Weco is AIDE, an opensource MLE Agent we developed that has been credited by OpenAI. In their independent evaluation, MLE-Bench, AIDE was shown to be the top-performing system for this class of task.
This is significant. Benchmarks are most useful before they are widely known and overfitted - before Goodhart's Law kicks in. AIDE's performance on this fresh, independent benchmark demonstrated the power of our design. AIDE has since been adopted and used by researchers at institutions like Meta, DeepMind, and Sakana, effectively becoming an industry standard.
Weco is the next evolution of this giving you more control, and work be plug into an existing code base, just like parallelly developed system, Google's AlphaEvolve.
Thriving in a Live Competition
Static benchmarks are vital, but can an AI agent compete against skilled humans in a live competition for real stakes? Especially when the solutions aren't already part of an LLM's training data?
To test this, we entered Weco into the CrunchDAO ADIA structural break prediction competition:
- The Stakes: A live, ongoing competition with a $100,000 reward pool, attracting hundreds of skilled data scientists.
- The Setup: We provided the agent only with the competition description and our evaluation script.
- The Process: The agent autonomously explored over 120 distinct solutions in 17 days, testing different feature engineering pipelines and model parameters with zero human intervention.
- The Result: We placed 34th out of 490 teams (Top 10%) on the private leaderboard. The automated run that leads to this solution cost just $20.
This case study highlights the new role of the ML engineer. Our time was spent refining the evaluation script to provide a clear signal, not manually trying a hundred ideas. You can explore the full dashboard for this run here to see every idea the agent tried.
What Real-World Impact Has Weco Delivered?
This methodology isn't limited to one domain. We're seeing early users apply it across the entire ML stack to get tangible results.
- Prompt Engineering for VLMs An astrophysicist used Weco to systematically optimize prompts for a Vision Language Model (VLM), improving the model's accuracy by 20%.
- Building Robust Agentic Scaffolds Startups are using the platform to optimize the accuracy and cost of their AI features, automatically finding the right balance between different models, prompts, and logical flows.
- Model Inference Speedup A researcher at a frontier AI lab used Weco for automated kernel engineering. By letting the agent explore the solution space, they made a new operator run 7x faster than their pytorch baseline.
- And More... The same loop is being applied to tweaking network architectures, optimizing complex rule-based image processing pipelines, and more.
How Do You Get Started with Weco?
Stop losing time to the manual grind. Start systematically exploring your idea space and find out what works.
Get started in 5 minutes with the Hello World example.