Evolving a Flappy Bird AI: 100 Solutions Explored, 6.6x Improvement, $12

We gave Weco a simple Flappy Bird AI that scored 2.76 points on average. 100 iterations and $12 later, the AI scored 20.9, a 6.6x improvement, with no human guidance beyond the initial setup. Here's how it works.
Key Takeaways
- Weco improved a Flappy Bird AI from an average score of 2.76 to 20.9 (6.6x improvement) for approximately $12.
- The optimizer autonomously explored 100 solutions, discovering strategies like trajectory prediction and look-ahead blending.
- No human guidance was needed beyond providing the initial code and evaluation metric.
- The search tree shows how Weco branches, backtracks, and evolves code through iterative experimentation.
The Setup
Flappy Bird is a perfect testbed for code optimization. The game is simple (tap to flap, dodge pipes, don't die) but writing a controller that consistently scores high is surprisingly hard. Pipe gaps vary in height, the bird's physics create non-trivial dynamics (gravity, terminal velocity, flap impulse), and a single misjudgment means game over.
We wrote a baseline controller in Python: a should_flap(observation) function that
takes the bird's position, velocity, and pipe locations as input and returns True or False. The
baseline uses a simple strategy: compute a safe zone within the next pipe gap, flap if below it.
It works, barely. Average score: 2.76 across 30 evaluation seeds.
Then we pointed Weco at it. After running pip install weco && weco setup, we opened
Claude Code and typed:
/weco optimize the flappy bird controllerThe Weco agent skill takes it from there: it figures out how to evaluate the code (average score over 30 game seeds), then kicks off the optimization run. No reward shaping, no architecture search, no hyperparameter tuning. Just "here's the code, make it better."
How Weco Works
Weco uses evaluation-driven code optimization, a tree-search algorithm that treats code as the search space and evaluation metrics as the objective. At each step, Weco:
- Selects a promising parent solution from the search tree
- Generates a mutated variant using an LLM
- Evaluates the variant against the metric (here, average game score over 30 seeds)
- Updates the tree with the result
This is different from single-shot code generation. Instead of asking an LLM to write the best controller it can in one try, Weco evolves the code over many iterations, keeping what works and discarding what doesn't. Each iteration builds on the best solution found so far.
The Search Tree
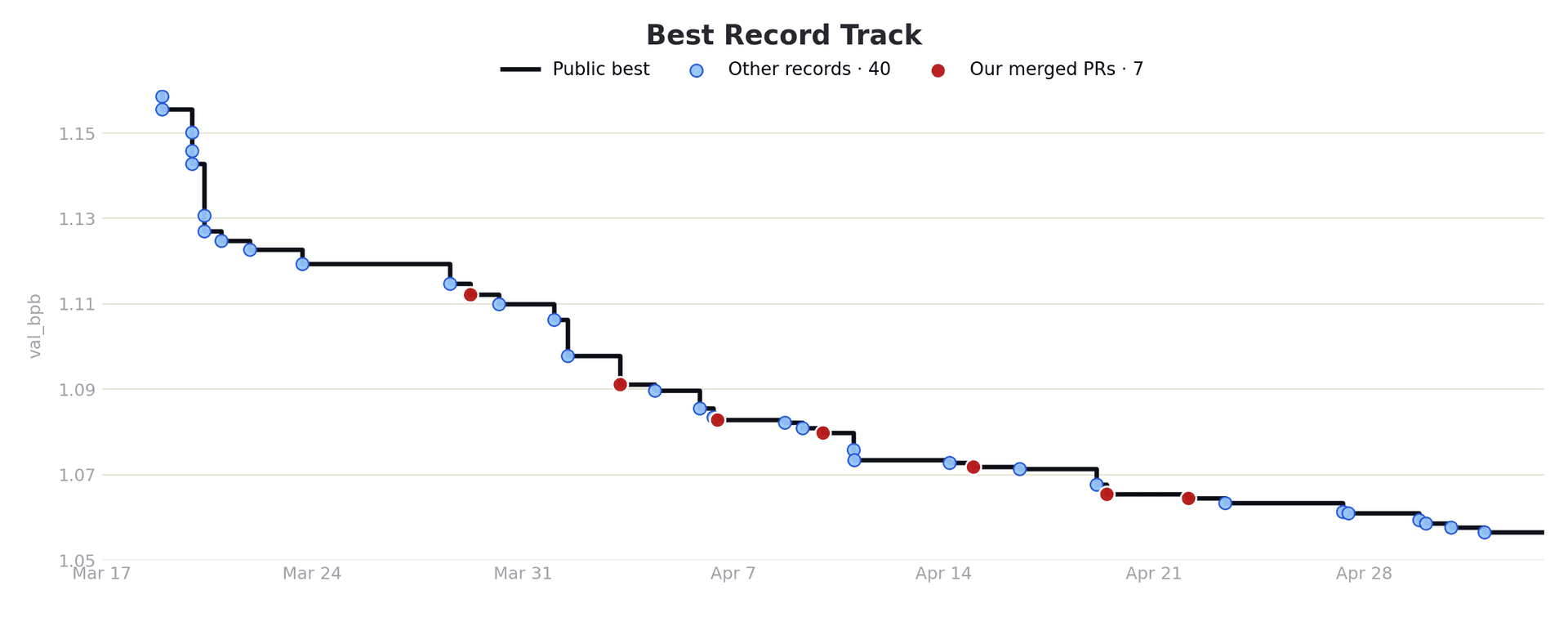
Over 100 iterations, Weco explored a tree of 101 solutions. Not all branches led somewhere useful. Some mutations broke the code entirely, others made the AI worse. But the successful mutations compounded.
Explore the full search tree interactively →
The best path through the tree passed through 11 nodes, with each breakthrough introducing a qualitatively different strategy:
- Step 0 → 6 (score 3.2 → 4.1): Cleaned up the baseline, tightened margins
- Step 6 → 18 (4.1 → 9.9): Added trajectory prediction, simulating the bird's future position before deciding to flap
- Step 18 → 27 (9.9 → 16.9): Introduced look-ahead to the next pipe, not just the current one, blending targets based on distance
- Step 27 → 84 (16.9 → 20.9): Refined adaptive margins, descent handling for downward pipe transitions, and velocity dampening
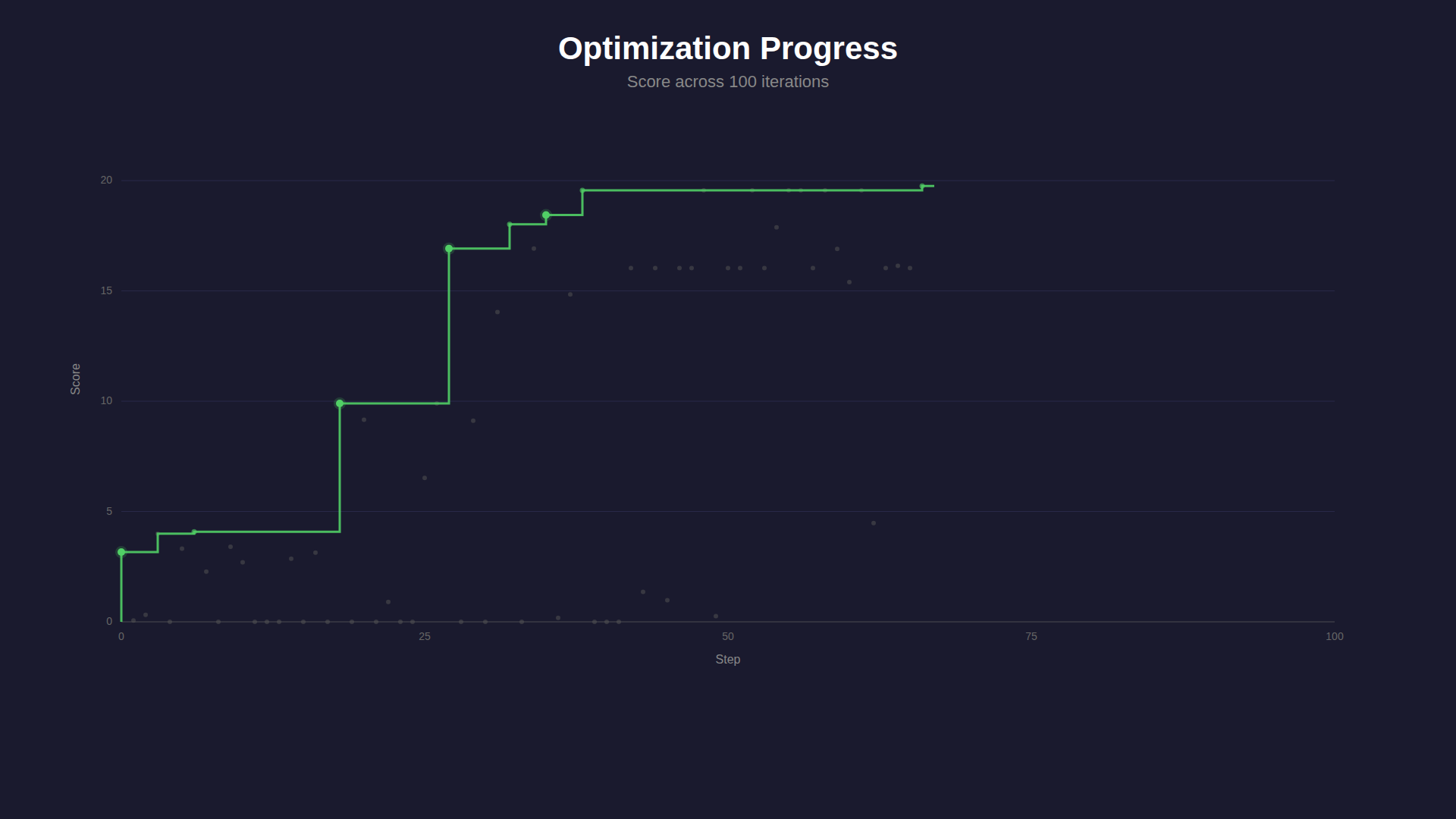
Optimization progress over 100 iterations. Green dots mark breakthroughs on the best path.
What Changed in the Code
The baseline controller was 71 lines (mostly comments explaining game physics). The optimized controller is 82 lines of pure logic. Here are the key differences:
1. Trajectory Prediction
The baseline just checks "am I below the target?", a reactive strategy. The optimized version simulates the bird's physics forward by 2–4 frames (depending on distance to the pipe) and acts on where the bird will be, not where it is now.
# Predict bird position
predicted_y = bird_y
predicted_v = bird_velocity
for _ in range(prediction_frames):
predicted_v = min(predicted_v + GRAVITY, 10.0)
predicted_y += predicted_v2. Look-ahead Blending
Instead of only targeting the current pipe gap, the optimized AI blends its target between the current and next pipe. When far away, it weights the next pipe more heavily (60%), preparing for the transition. When close, it focuses entirely on the current pipe.
# Dynamic target blending based on distance
if next_pipe_dx > 150:
target_gap_cy = 0.4 * next_pipe_gap_cy + 0.6 * after_pipe_gap_cy
elif next_pipe_dx > 80:
blend = (next_pipe_dx - 80) / 70
target_gap_cy = (1 - blend) * next_pipe_gap_cy + blend * after_pipe_gap_cy3. Adaptive Margins
The baseline uses a fixed margin of 19 pixels. The optimized version tightens the margin when close to a pipe (12px) and widens it when far away (22px), giving the bird more room to maneuver when it has time, and precision when it needs it.
4. Descent Handling
When the next pipe gap is significantly lower than the current one, the optimized AI recognizes the downward transition and adjusts its velocity dampening thresholds. This prevents the common failure mode of overshooting upward when approaching a lower gap.
None of these strategies were specified in advance. Weco discovered them through iterative mutation and evaluation, the same way biological evolution discovers adaptations, but in minutes instead of millennia.
Results
| Baseline | Optimized | |
|---|---|---|
| Average score (30 seeds) | 2.76 | 20.9 |
| Max score (best seed) | 11 | 88 |
| Controller lines | 71 (mostly comments) | 82 (pure logic) |
| Strategy | Reactive safe-zone targeting | Predictive + look-ahead + adaptive |
Total cost: ~$12. Total time: ~30 minutes. The optimization ran 100 iterations, each calling an LLM to generate a code variant and then evaluating it against 30 game seeds.
Try It Yourself
Weco isn't just for games. The same evaluation-driven optimization works on any code with a measurable metric: model training, data pipelines, API performance, prompt engineering.
pip install weco && weco setup
This installs a Weco agent skill into your coding agent (Claude Code, Cursor, or any
MCP-compatible agent). Then just type /weco optimize my code and the agent walks
you through everything, including building an eval if you don't have one yet.
You get $20 in free credits to start, or bring your own API key. Check out the documentation to get started.