AutoResearch vs Classical Hyperparameter Tuning

AutoResearch shows strong optimization power on NanoChat, while Karpathy and others pointed out a caveat: most of its accepted changes were just hyperparameter tweaks. This raises a natural question: how does an LLM agent compare to classical hyperparameter search algorithms that have been refined for decades? Is it more sample-efficient? Is it too expensive? Does it just overfit the eval?
To find out, we ran a head-to-head comparison on NanoChat: Claude Code + Optuna versus AutoResearch. AutoResearch shows superior performance across the board, yielding higher sample efficiency, better results under the same compute budget (even factoring in LLM token costs), and solutions that generalize better.
This extra optimization power comes down to flexibility. Because the agent edits code directly, it can break out of a predefined search space as it runs longer.
Let's break it down:
What is AutoResearch?
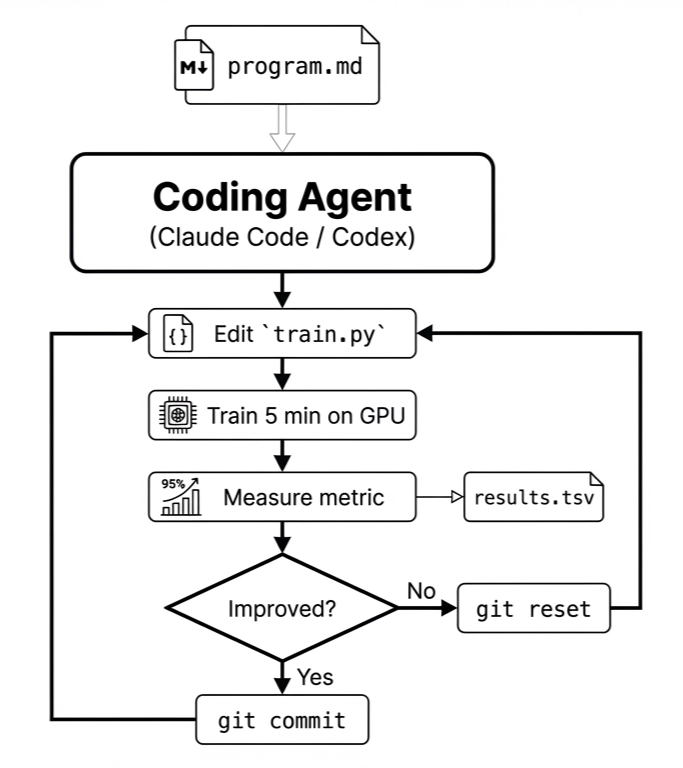
AutoResearch is a prompt. Karpathy released it as a single markdown file,
program.md, that instructs a coding agent (Claude Code, Codex, or similar) to
follow an optimization loop: edit a file, run an eval, check whether the metric improved, keep
or revert, repeat.
The specific instance he shipped targets LLM training: edit train.py, train for 5
minutes on one H100, measure validation bits-per-byte. But the structure of iteratively
optimizing code against an evaluation metric, with a discard/keep loop, is portable to anything
with a measurable objective.
The benchmark
To test the "just hyperparameter tuning" hypothesis directly, we ran Optuna's TPE against AutoResearch on the same task: 5 minutes of training on one H100, minimize validation bits-per-byte.
Setup
We used Claude Code to define Optuna's search space, it read train.py, identified
tunable knobs, and chose parameter ranges. This way both methods start with the same prior
knowledge: the agent has it implicitly (it reads the code before each experiment), and Optuna
has it encoded in its search space. The quality of a classical optimizer's prior matters
enormously, and a poorly chosen search space would be an unfair handicap.
The Optuna study searches over 16 hyperparameters: model depth, aspect ratio, head dimension, window pattern, six learning rates, weight decay, warmup/warmdown ratios, final LR fraction, and batch sizes. Trial 0's parameters match the NanoChat baseline exactly, so Optuna starts from the same point the agent does.
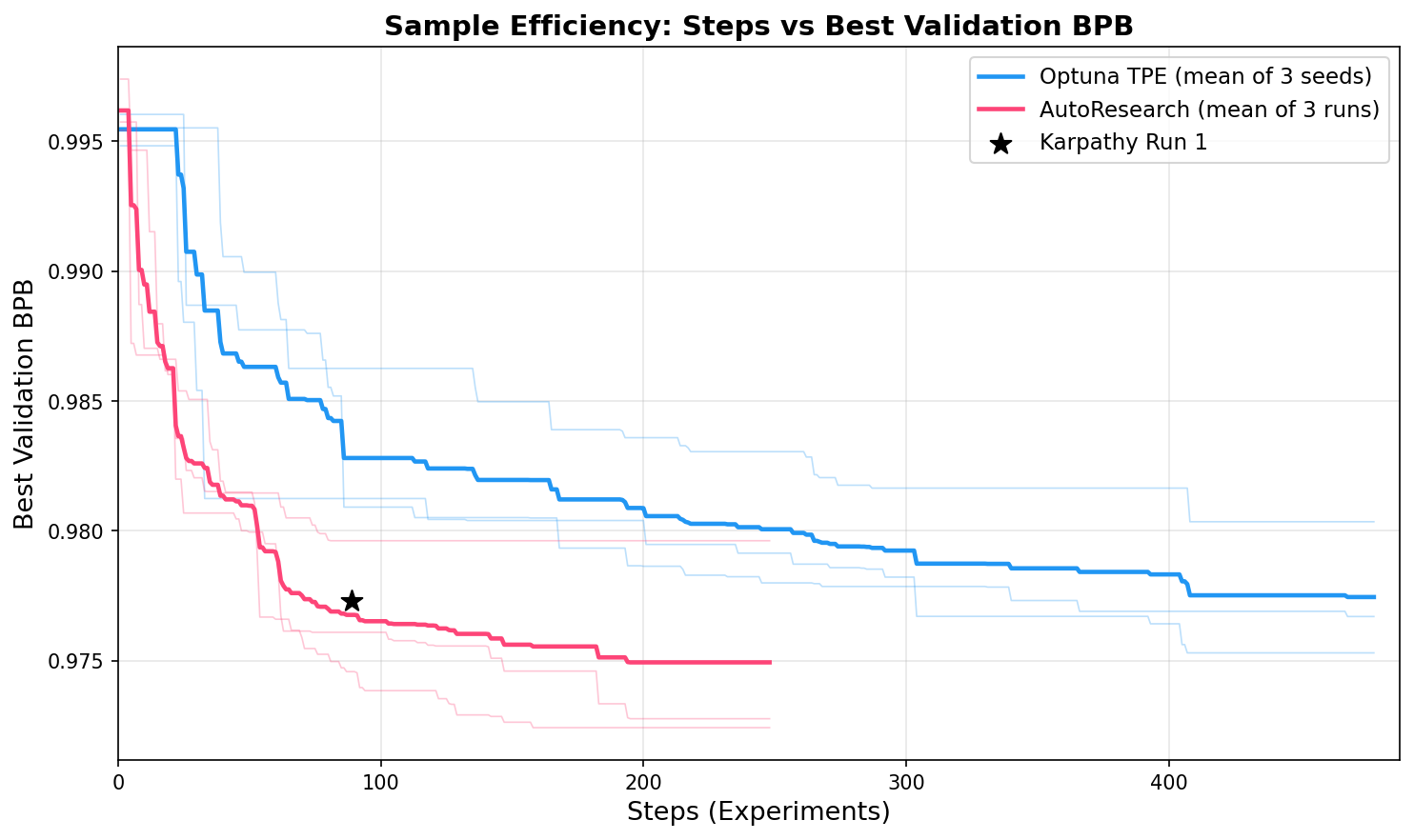
We run 3 seeds for each method. To keep the comparison fair, we fix the total compute budget: each method gets the same GPU-hours. Since AutoResearch costs ~2x per step ($0.84 vs $0.44, the LLM tokens add ~$0.40 on top of the GPU cost), Optuna gets roughly twice as many trials for the same spend. We also include Karpathy's own published Run 1 (89 experiments) as a community reference point.
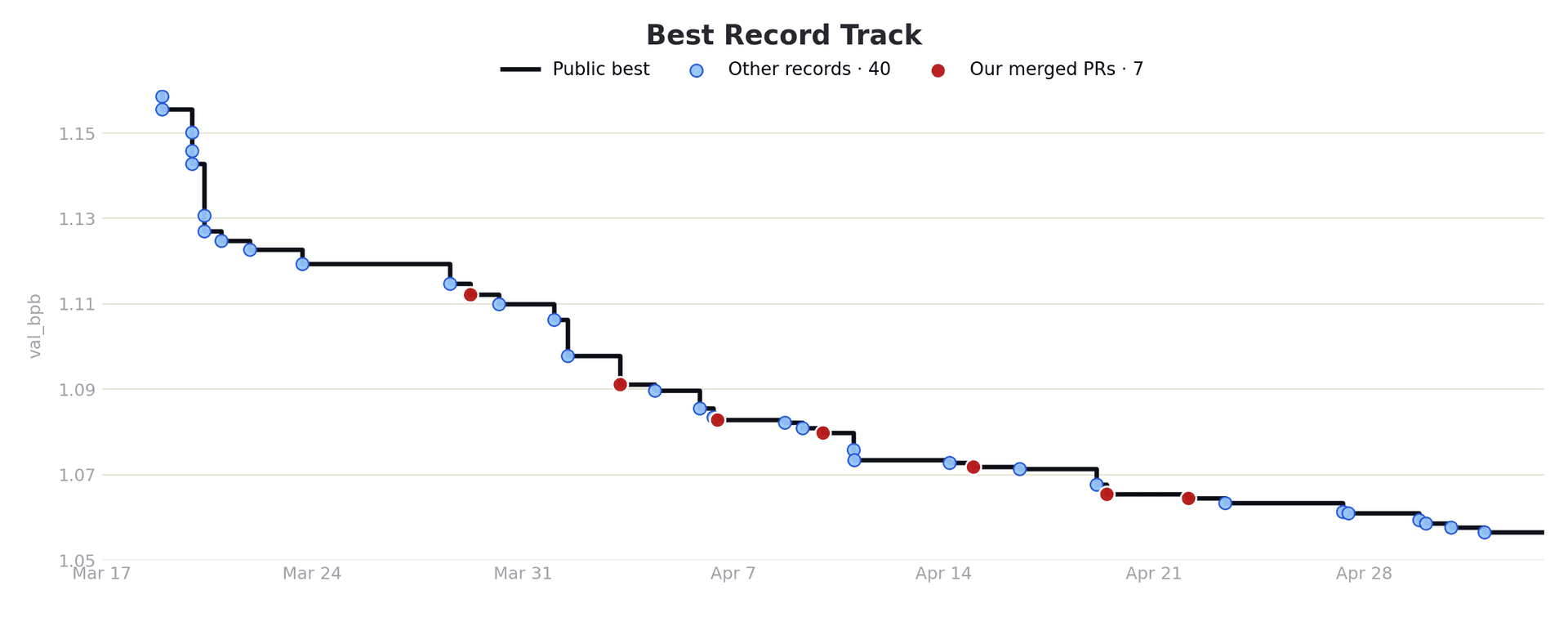
Sample efficiency
AutoResearch converges faster, reaching better solutions in fewer experiments at every step
count. This makes sense: the agent reads train.py before each experiment, so its
first moves are informed guesses rather than random samples. Optuna's TPE needs ~15–20 trials of
random exploration before its surrogate model kicks in.
Cost efficiency
Despite the 2x higher per-step cost, AutoResearch still comes out ahead across all cost budgets.
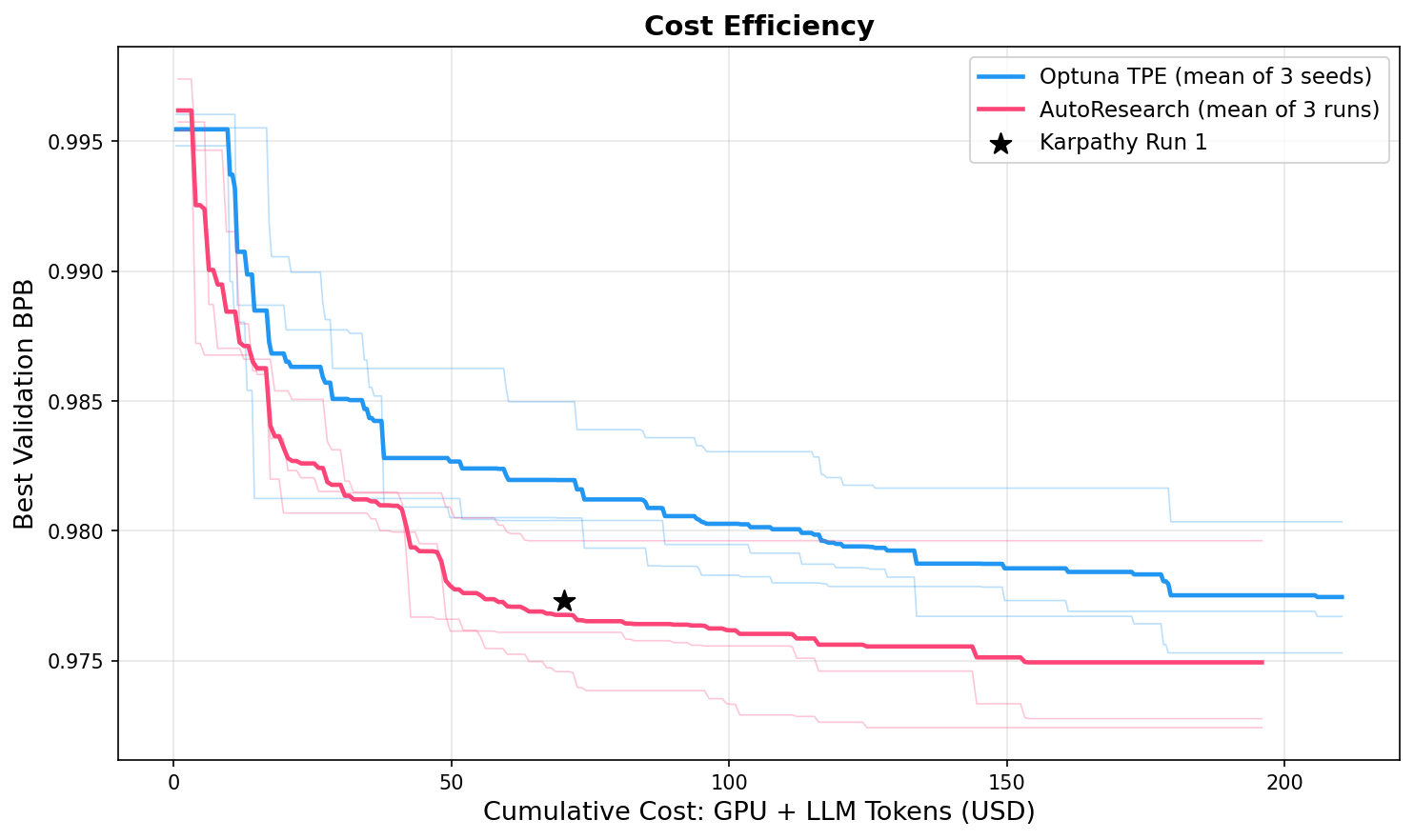
This conclusion is sensitive to evaluation cost. In our setup, each eval takes 5 minutes on an H100 (~$0.44), comparable to the LLM cost. If evaluation were much cheaper, say, a 30-second benchmark on a smaller GPU, LLM tokens would dominate and Optuna could run many more trials for the same budget, potentially closing the gap. The crossover point shifts as inference costs drop.
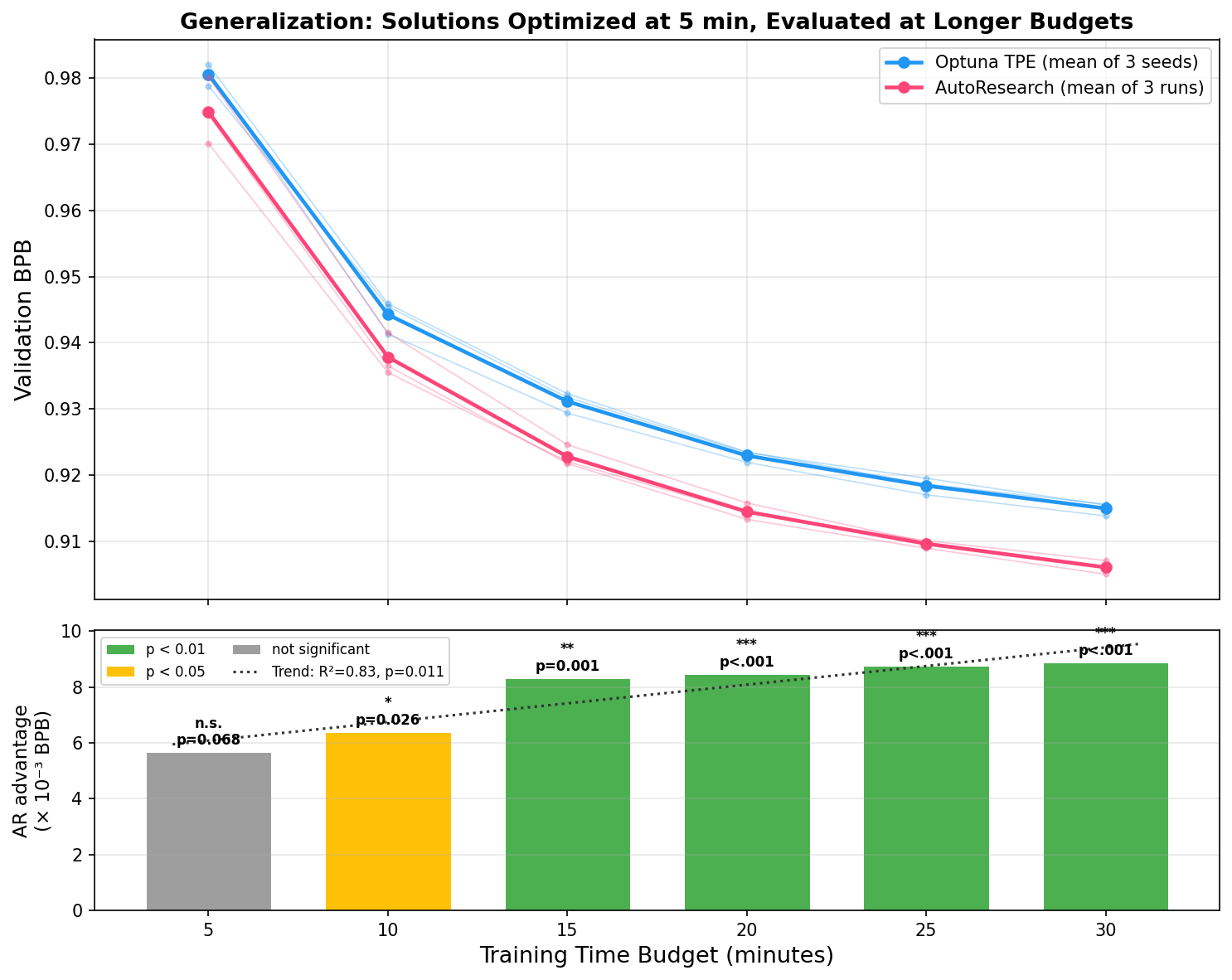
Generalization
Every solution above was optimized against a 5-minute proxy. But the real goal is a better training pipeline, not a better 5-minute score.
We took the best solutions each method found and gave them progressively more training time. AutoResearch's solutions generalize better: the absolute validation BPB gap widens with more compute, and the statistical significance strengthens.
Why AutoResearch outperforms classical HP optimization
A larger search space
We classified every kept experiment across all 3 runs by whether it fell within Optuna's 16-parameter search space (IN) or outside it (OUTSIDE):
| Run | IN | OUTSIDE | BPB from IN | BPB from OUTSIDE |
|---|---|---|---|---|
| Run 1 | 15 | 2 | 99% | 1% |
| Run 2 | 16 | 11 | 77% | 23% |
| Run 3 | 12 | 19 | 57% | 43% |
Averaged across seeds, ~78% of the agent's improvement comes from the same knobs Optuna has access to. Run 1 is the natural control: when the agent only does hyperparameter tuning, it's roughly equivalent to Optuna on the eval metric. The extra ~0.007 BPB that separates Runs 2 and 3 from both Run 1 and Optuna comes from changes outside the predefined search space.
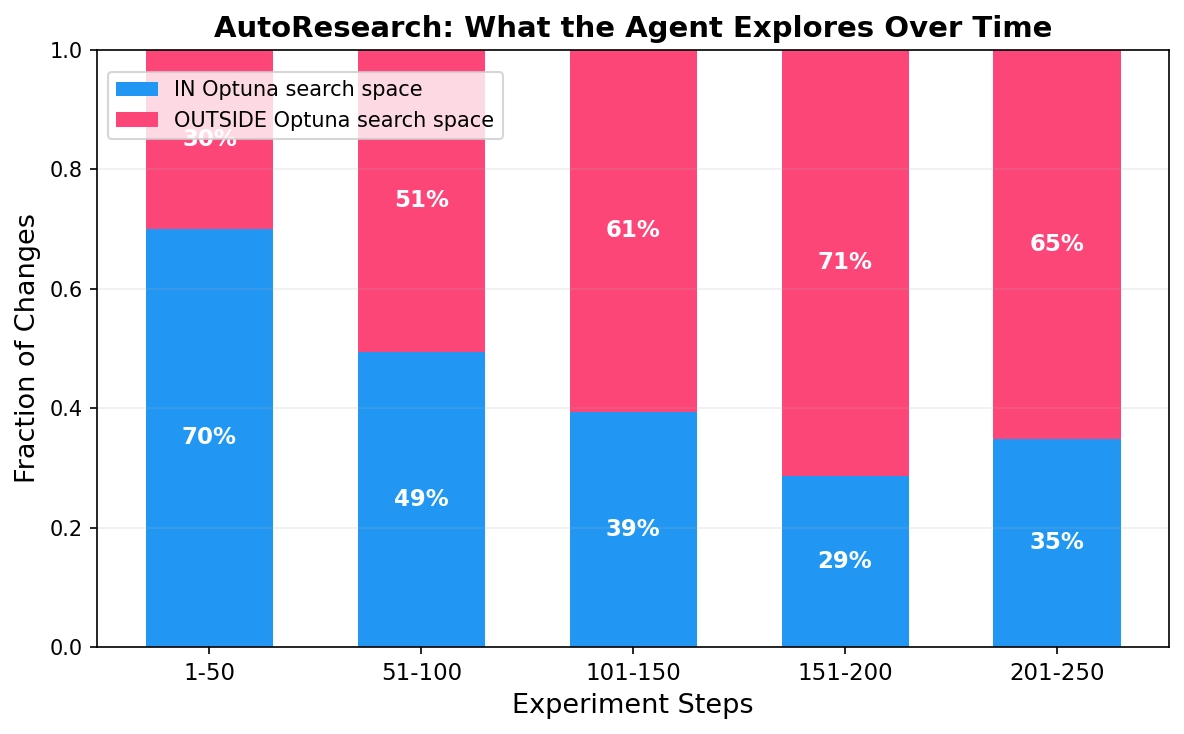
The pattern across run 2 and 3 is the same: the agent exhausts hyperparameter knobs early, then pivots to code-level changes. In the first 50 steps, ~70% of experiments are in-space. By step 150+, ~70% are outside.
Those out-of-space changes fall into two categories.
Undiscovered hyperparameters. Values in the code that could be parameterized, they're technically just numbers, but claude code didn't think to include in the search space at first:
- Short attention window (Runs 2 & 3): shrinking the sliding window from seq_len/2 to seq_len/16 (128 tokens). Optuna searches over window patterns (SSSL, SSLL), but the window size in tokens is hardcoded. The single largest out-of-space contributor.
- RoPE base frequency (Run 3): 10K to 100K. One constant, one line.
- Softcap value (Run 3): attention logit capping 15 → 14.
- Gradient clipping (Run 3): the baseline has no clipping. The agent added it, then tuned through 1.0, 0.5, 0.7, 0.8.
- Muon optimizer internals (Runs 2 & 3): beta2, momentum ramp schedule, momentum target, distinct from the Adam betas Optuna tunes.
Any of these could be added to Optuna's search space in hindsight. But that's the point: you'd need to know they matter first. The agent discovers which knobs to turn, not just what values to set them to.
Structural changes. Modifications that can't easily be reduced to a number or an enumeration:
- Norm before RoPE (Run 2): inserting a normalization layer before rotary embeddings. A new layer that didn't exist in the baseline. Worth 0.0013 BPB.
- Initialization schemes (Run 3): changing embedding init to std=0.5, c_proj init to 0.01/sqrt(n_layer), unembedding init to 0.005. Not different numbers for the same function, different functions.
- Value embedding gate init (Run 2): switching from zero initialization to small random values.
These are hard to express in classical HP optimization. You can't enumerate "all possible architectural changes" as a search space.
Implicit Regularization
One interesting fact is run 1 made few out-of-space changes and finished at 0.9796, which is similar to optuna (0.9753-0.9804, mean 0.9775). However, it generalizes better at longer training horizons. It seems like the autoresearch agent isn't blindly optimizing a score. Our hypothesis is LLM's knowledge about good training practices serves as an implicit regularization mechanism for the optimization.
Conclusion
AutoResearch's edge comes from two things: an LLM prior that makes informed changes rather than blind samples, and access to the full code space rather than a predefined parameter vector. The first makes it sample-efficient and helps its solutions generalize. The second gives it a higher ceiling.
Neither advantage is specific to LLM training. Anything with a measurable objective and editable code is a candidate, which is why the community has already applied it to prompt engineering, backend optimization, and formula discovery. We have a curated list here.