How to Build a Good Eval

"Vibe driven development" sounds like a joke, but it's the default methodology for most AI agent teams. The workflow - change something, run the agent, eyeball the output, decide if it's better. This is an eval loop, one with a sample size of one, no reproducibility, and a loss function that lives entirely inside one person's head.
Most teams know this isn't sustainable. But what comes next is where they get stuck. Some reach for an eval framework and assume the tooling is the eval. Others, having seen enough benchmarks get gamed, conclude that rigorous evaluation is a research problem too deep to be practical.
Both reactions share a root cause, not having built an eval pipeline from scratch and iterated an agent or model against it. Eval is neither a tool you install nor a paper you need to publish. It's a specific way of thinking, one that comes from experimental science, not software engineering.
This post is about that way of thinking.
Key Takeaways
- Eval is not a tool you install. It is a way of thinking rooted in experimental science, not software engineering.
- An eval is a simulator that tells you whether changes made things better or worse before you deploy, unlike observability which reports what happened after.
- Good benchmarks balance Fidelity (how well they predict real quality), Signal (how robustly they differentiate solutions), and Cost (money and time to run).
- Maintain separate validation and test sets to prevent overfitting. Optimize against validation daily and run test rarely before releases.
White Box vs Black Box
In traditional software, code is a white box. You can read the logic, trace the execution,
verify correctness by inspection. If x > y then do z, and you know the logic is
right, the output is correct. Tests are a safety net for when your reasoning is wrong.
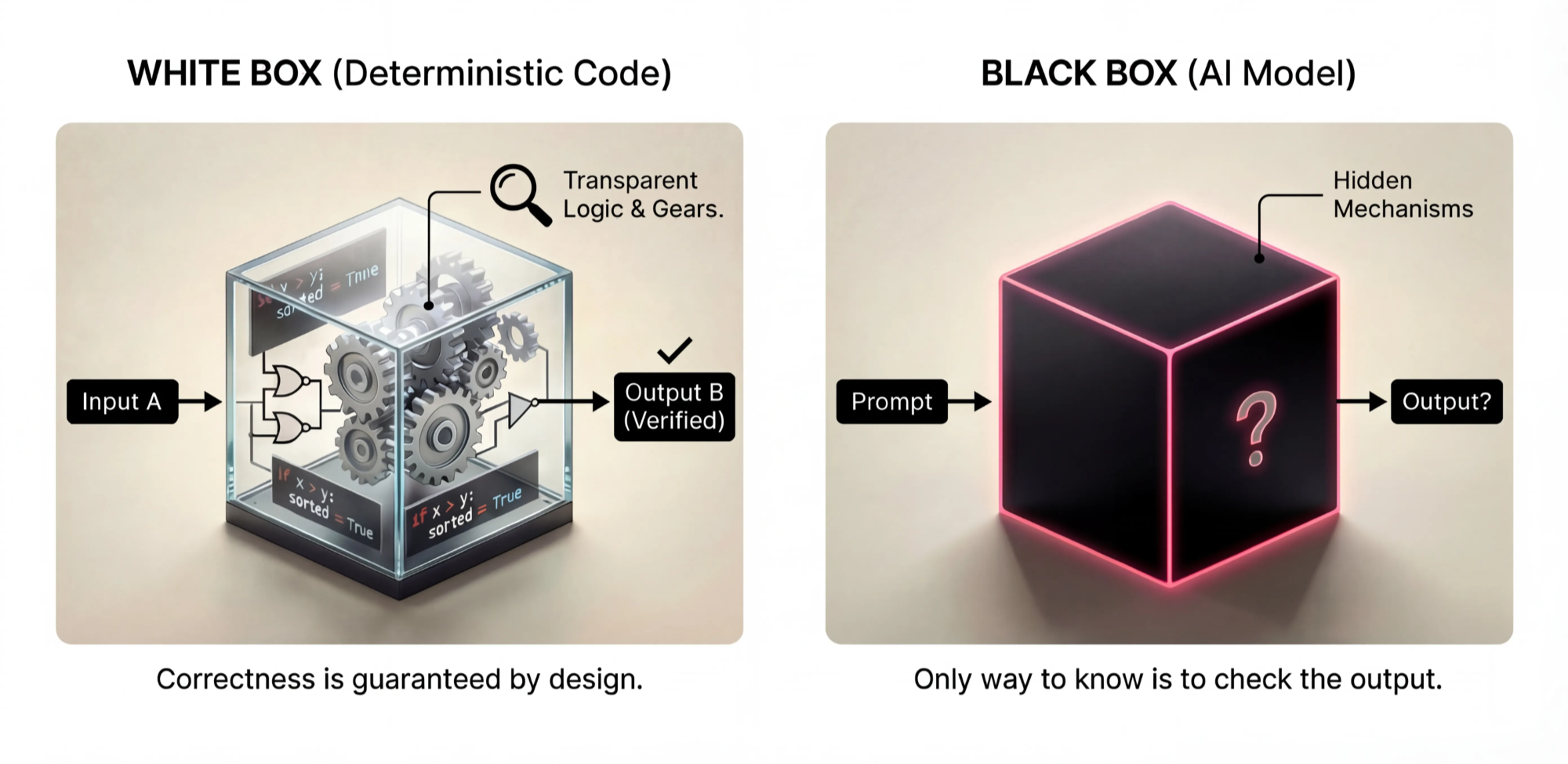
An AI model is a black box. You feed it a prompt, it returns an answer, but the internal logic is opaque. The "code" is billions of weights you cannot read. Worse, the system is inherently probabilistic and the capability frontier is jagged. It might handle 80% of cases and fail unpredictably on the other 20%.
You cannot verify correctness by reading the code, because there is no code to read. You have to measure correctness empirically, across many inputs. This is why you need an experiment, not just a unit test.
This distinction matters because many engineers approach AI systems with their white box intuition intact. They write a prompt, test it on a few examples, see it working, and conclude it works. In a white box, this reasoning is valid. If the logic is right, it's right everywhere. In a black box, "works on my examples" tells you almost nothing about the other cases.
What Is an Eval and Why Is It a Simulator?
It's tempting to think that the third party tooling solves this. Langfuse, Braintrust, LangSmith, Promptfoo - the ecosystem is growing fast. But it's worth understanding what these tools actually are. They are observability platforms first. Their core job is monitoring your production pipeline - tracing, logging, cost tracking. Eval features (prebuilt LLM judge templates for hallucination, toxicity, relevance) are added on top.
This matters because observability and evaluation are fundamentally different activities. Observability tells you what happened in production, after the fact. An eval is a simulator. It tells you whether a change made things better or worse before you deploy. You construct a proxy of the real world, run your agent against it offline, and compare scores. It can be as simple as a Python script and a CSV file.
If you start from an observability platform and try to add eval, your thinking starts from "what's happening in production." If you build an eval from first principles, your thinking starts from "what does good look like, and how do I measure the distance from it." These lead to very different outcomes.
The prebuilt templates can get you started if your use case is generic enough (say, a customer support chatbot). But for most agentic workflows, the real questions are ones no template answers for you. Which brings us to the key question, what makes a good eval?
What Makes a Good Eval?
A benchmark is your proxy for real world utility.
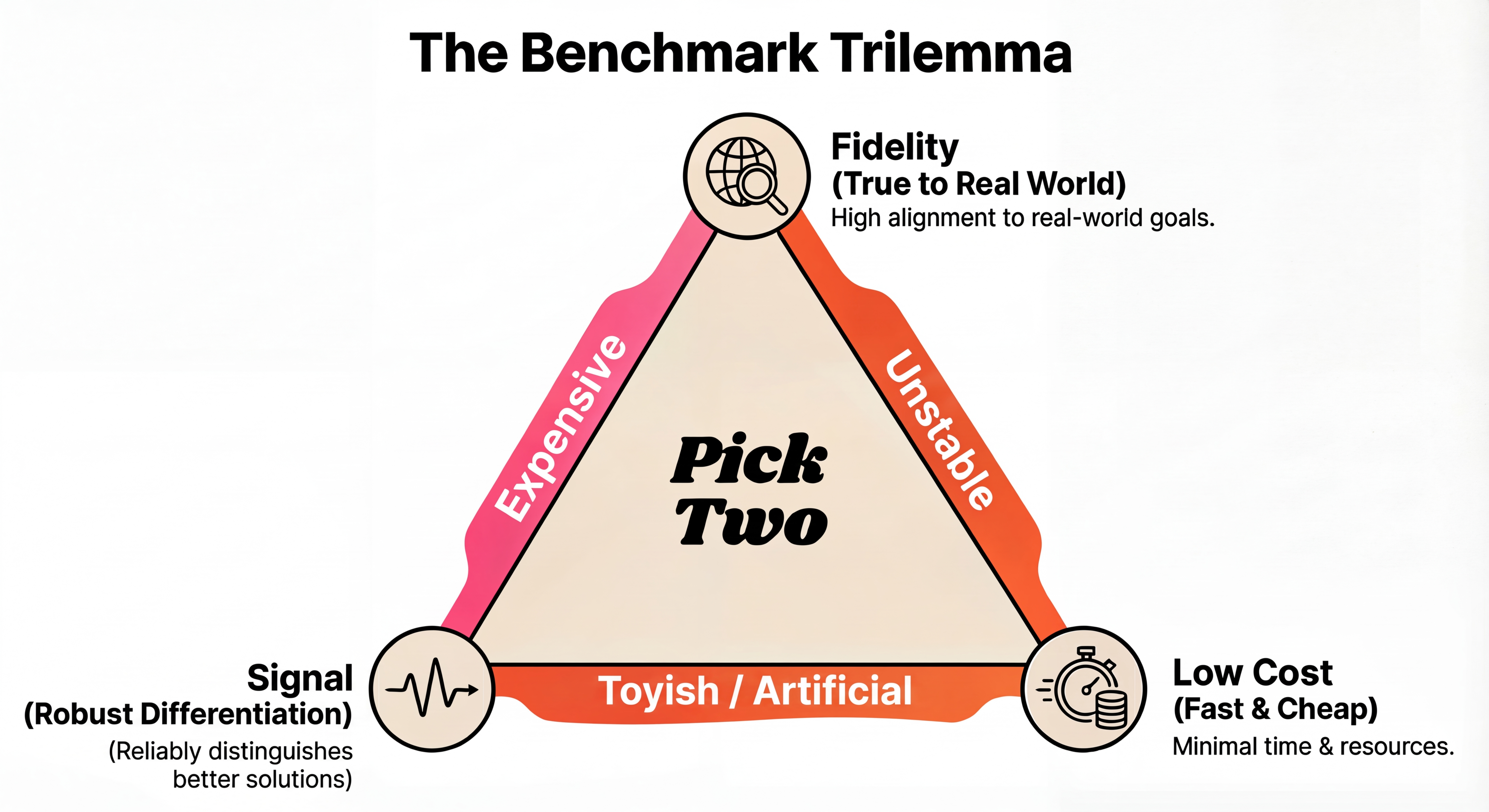
There are three key variables to consider - Fidelity, Signal, and Cost.
Fidelity - How well does the benchmark result predict the actual end to end quality you care about? Instead of just statistical correlation, think of this as "Ground Truth Alignment". In practice, you want your benchmark to be as close to the real experience as possible.
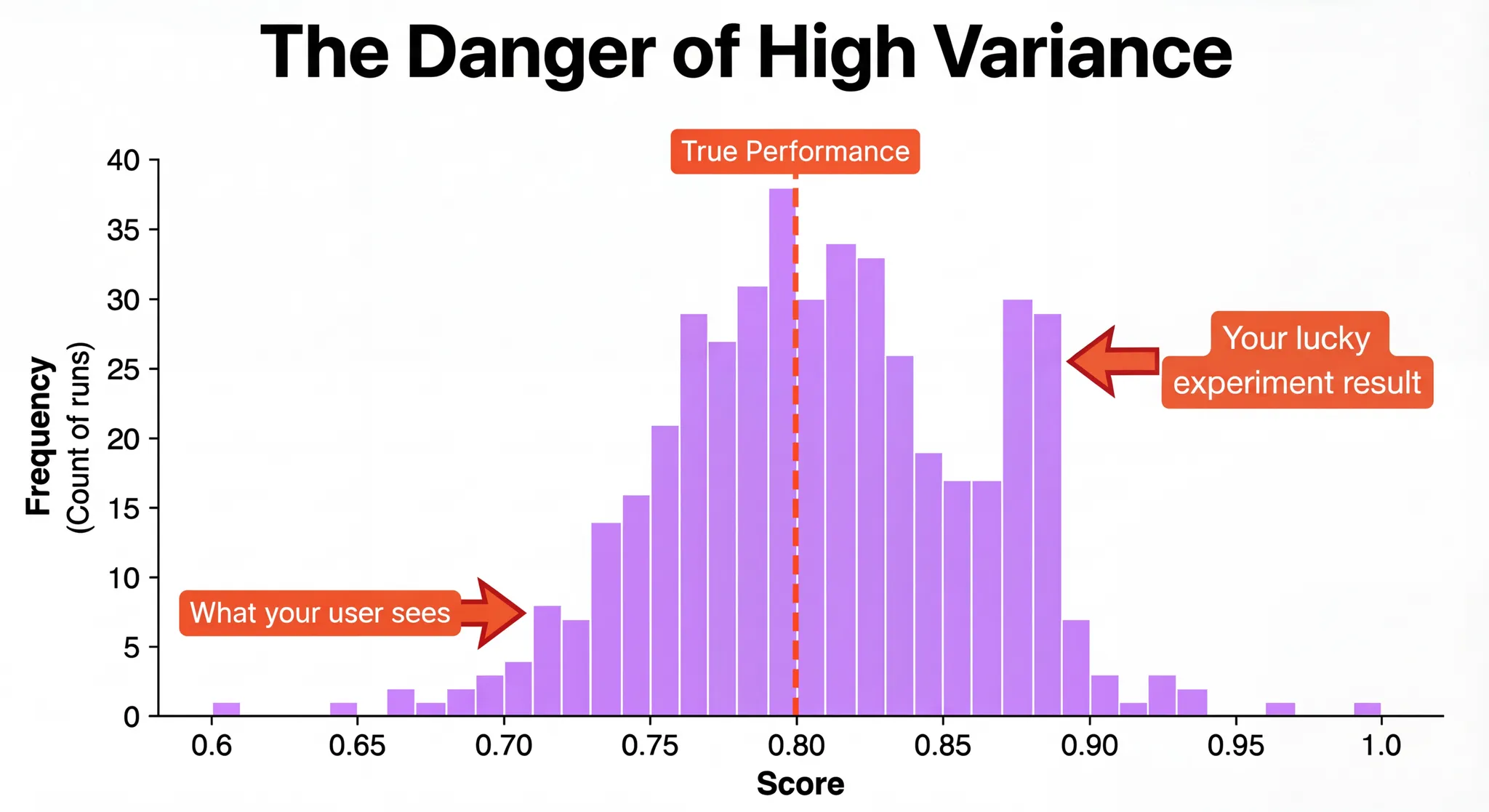
Signal - The benchmark should robustly differentiate two solutions. A benchmark can be saturated (all solutions perform quite well) or have high variance (run the benchmark multiple times and you'll get different results). In both cases, the conclusion you draw from it might not be statistically significant.
Cost - Running benchmarks costs money and time. It is possible to optimize for cost, but often at the expense of signal or fidelity.
It is very difficult to optimize all three at the same time. For example, you can reduce the variance of the final score by running the same eval multiple times at a higher cost. A good rule of thumb - start with a cheaper evaluation with decent fidelity. As you pick the "low hanging fruit" improvements, you can gradually build a high signal benchmark to capture more nuanced signals. You should be aware of these three dimensions throughout the process.
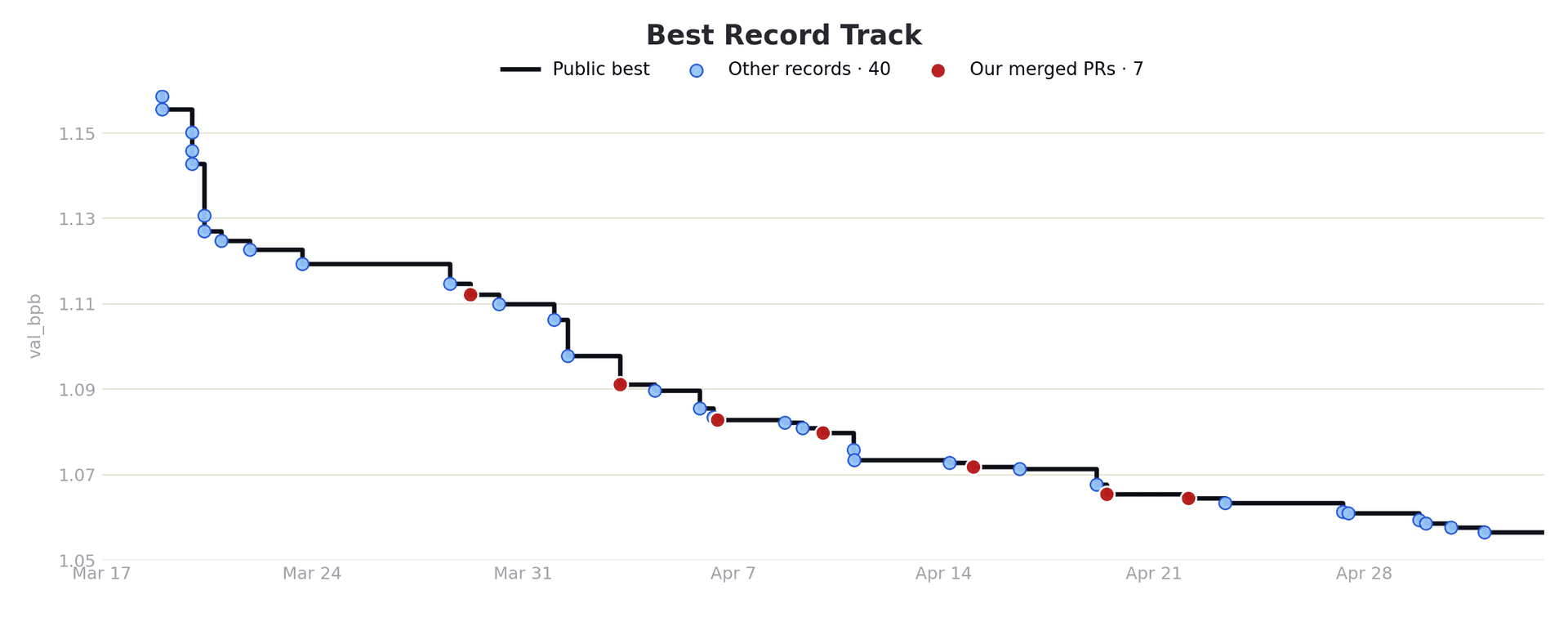
Why Are Vibes an N=1 Benchmark?
A common objection to benchmarks is Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure." The more you optimize against a specific benchmark, the more you risk overfitting to its quirks rather than improving actual quality.
This is a real concern. But the alternative is not "no benchmark"; it's a worse benchmark.
If you're optimizing against your vibes, you are running a benchmark. It just has N=1 (or maybe N=5) data points, no reproducibility, and a scoring function you can't inspect or improve. You are still overfitting, but now you can't even detect it.
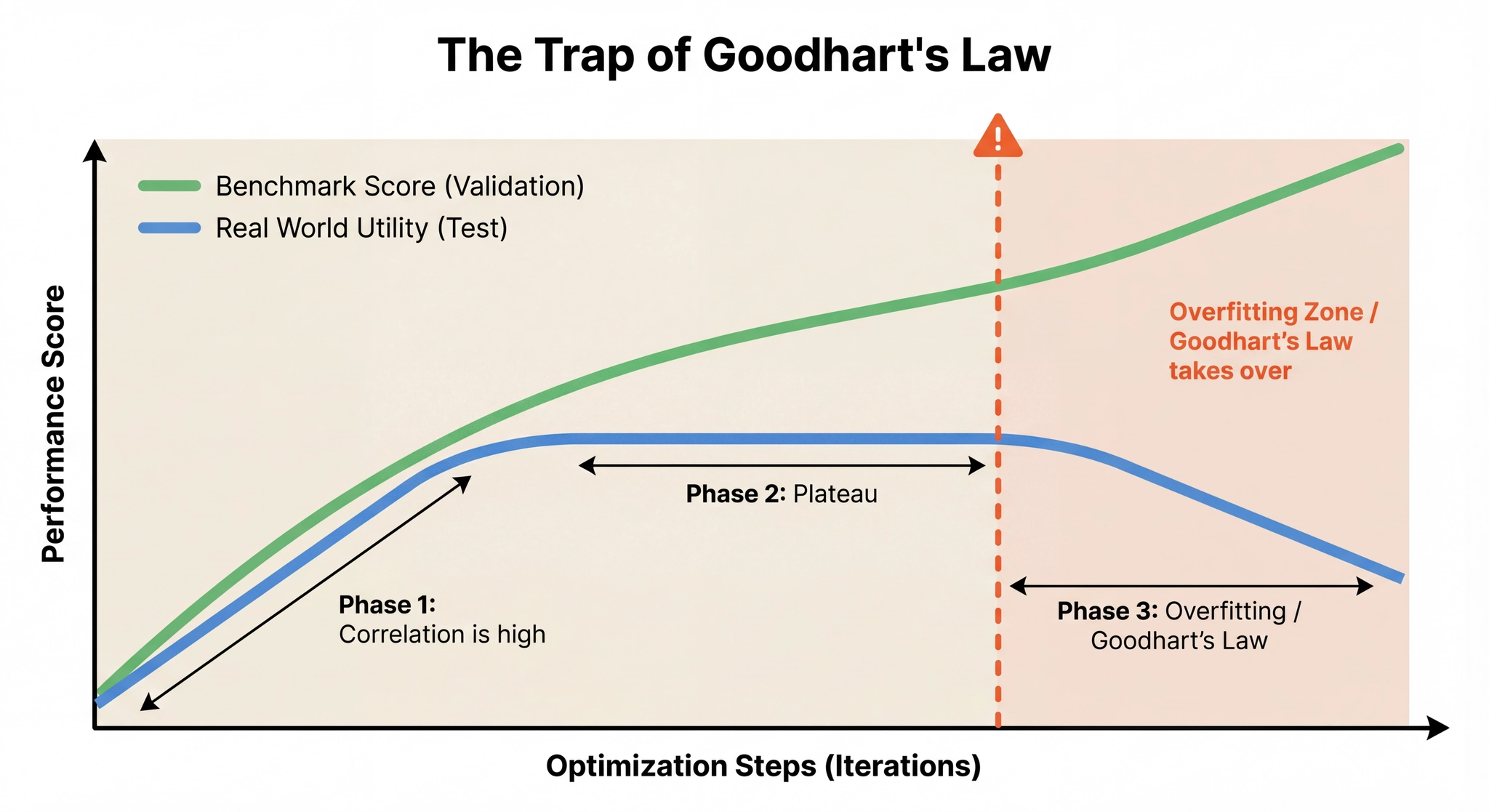
The solution is not to avoid metrics. It's to treat your benchmark as a living thing that needs iteration.
Maintain separate validation and test sets. Optimize against validation daily. Run test rarely, before releases, to check if improvements generalize. If validation goes up but test flatlines, you're overfitting. The right response is not to start optimizing against test. It's to increase the size and diversity of your validation set.
Prune saturated data points. If your agent scores 100% on certain tasks consistently, those samples are costing money without generating signal. Move them to a cheap regression suite and replace them with harder examples.
Review your assumptions. If users complain but your score is high, your metric is wrong or your data is unrepresentative. Go back and fix the benchmark, not the users.
Building an eval is not a one time task. It's the ongoing process of aligning your engineering loop with reality.
We're studying how teams build evals for agentic workflows in practice. If you're working on this and want concrete feedback on your eval design, reach out at contact@weco.ai. Tell us what you're evaluating and how you're scoring it.